云中断来了,你的数据库扛得住吗?
就在昨天,中东某地区发生了一场大规模的云基础设施中断事件。阿联酋某『数据中心』遭遇物体撞击起火。消防部门赶到现场后,被迫切断整栋设施的供电。断电意味着什么?意味着那个可用区里,所有跑在上面的服务,全部失联。官方通报说,受影响可用区的服务恢复“需要数小时”。
几小时——对一个订单系统来说,是灾难级的窗口。对一个全球用户都在线的产品来说,是你在『社交媒体』上被骂烂的时长。对一个 IT 团队来说,是你在会议室里对着屏幕干瞪眼、什么都做不了的煎熬。
这不是演习,不是单点服务的小抖动——整个地域的可用性骤降,波及大量企业的核心业务系统。许多公司的『工程师』在紧急上线,试图切换备用方案,但大多数人发现:他们以为有备份,实际上没有真正意义上的容灾。
冷备?恢复需要数小时。
同云多 Region?有跨 Region 容灾的团队确实恢复更快——但也有团队发现,备用 Region 从没演练过,切换链路上的 DNS、连接配置、容量验证一个都没跑通,故障现场比没有备用方案还乱。
手动切换?没操练过的流程,故障现场反而更乱。
很多团队事后复盘时都会发现一个事实:“我们以为我们的架构是高可用的,直到它真的崩了。”
这篇文章写给那些还没经历过这种场景、但绝对不想踩到它的『工程师』和技术负责人。
继续往下读之前,先做一个自查
以下 4 个问题,命中任意 1 条,这篇文章值得你读完:
你的数据库部署在单一云厂商的单一 Region,没有跨云备份?
你有备份,但从来没有完整演练过“备份恢复到可用状态”需要多长时间?
你的国内业务在 A 云,海外业务在 B 云,两套技术栈让团队运维成本居高不下?
你的业务对 RTO(恢复时间)有明确要求,但现在没有 SLA 数据可以证明你能达标?
先把一个常见误区讲透:同云多 Region,仍可能不够
大多数数据库都提供了完善的单云高可用能力:多 AZ 部署、跨 Region 备份、自动故障切换……在大多数时候,这些能力足够应对日常的节点故障和机房问题。
但“有备份”不等于“有容灾”。故障域未必被真正隔离,控制面、核心依赖服务、配额/限流策略等,仍可能同源。
“能切”不等于“切得动”,跨 Region 的切换牵涉到 DNS、路由、证书、访问白名单、密钥托管、依赖服务等一整条链路。
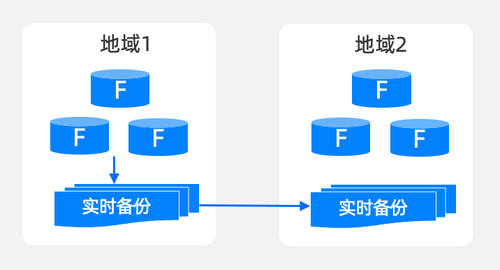
演练缺失会放大故障,没有完整演练的数据恢复、业务回切、容量验证,在真实故障里往往会变成“第一次上生产”。OB Cloud 的设计从一开始,就把多地域、多云跨、云纳入容灾能力矩阵,形成面向多云高可用体系,解决“地域级/云厂商级”的不确定性。
OB Cloud 高可用的 4 个层级
很多人讨论“高可用”时说的是同一件事,但实际上高可用有四个完全不同的层级。
层级 1:节点级
『服务器』宕机,业务无感知
OceanBase 原生分布式多副本架构,基于 Multi-Paxos 协议,节点故障时集群自动选主,无需人工介入,业务连接中断时间通常可控制在秒级。
这是最基础的能力,也是许多传统数据库需要额外配置才能实现的能力。
层级 2:机房级
同城 IDC 故障
三副本跨机房部署,支持 2F1A 模式(两个全功能副本 + 一个仲裁节点),在机房级故障下自动切换,成本比传统三全功能副本降低约 1/3。
层级 3:Region 级
整个地域故障
全功能副本实时同步/备份到另一城市的 Region,在合适的部署与链路条件下可实现接近 RPO=0 的恢复目标,并支持异地多活等架构形态。
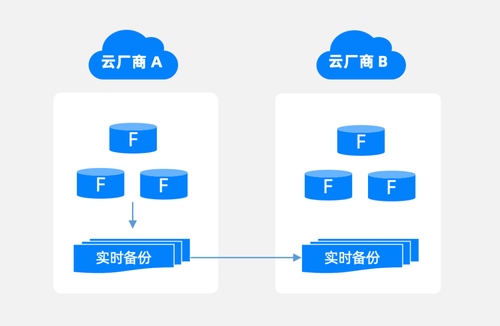
跨云容灾的三种模式:从兜底到核心系统可用
模式 A:跨云冷备
适合成本敏感型业务,主集群在云 A,备份与日志归档到云 B
跨云冷备适合 RTO 允许在小时级的业务,它解决的核心问题是“主云挂了还能救”。这类方案能带来的收益是:当主云不可用时,你仍能在另一朵云拉起并恢复数据,避免彻底失联。
落地方式是把主集群放在云 A,主集群数据备份和日志备份可以备份到另一朵云——云 B 的对象存储当中。当云 A 主集群发生故障时,基于云 B 的日志备份快速恢复生产业务。它的代价也很明确,恢复时间强依赖数据量与恢复流程,TB 级数据在极端情况下可能需要较长的恢复窗口。
模式 B:跨云热备
适合关键业务,可通过 OMS 近实时同步
适合 RPO 目标为分钟级、希望将恢复时间控制在较短窗口的关键业务。收益在于,近实时同步可降低数据回放量,使故障后切换到备端更可控、业务降级更轻。
落地方式是通过内置的 OceanBase 数据迁移工具,也就是 OMS,可以打通不同云厂商之间的数据同步链路,来实现从云厂商 A 到云厂商 B 之间的数据同步。当业务出现异常时,可以把业务流量切到对应的云厂商 B 上面去做业务容灾。

模式 C:跨云主备集群
面向核心业务,这是最能应对“厂商级故障”的方案
跨云主备集群更适合无法接受长时间中断、希望将故障域扩展到不同云的核心业务,并在可达网络条件下尽量降低对专线与复杂网络改造的依赖。风险覆盖面从“同一云的多 Region”进一步扩展到“跨云的主 Region”,切换与恢复更可控。
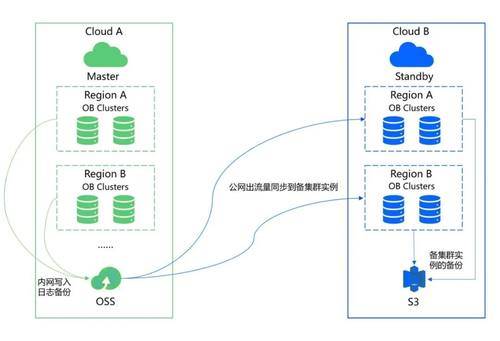
落地方式可以概括为:主实例在云 A(如国内某云),备实例在云 B(如海外某云),备实例通过访问主实例的对象存储日志实现数据同步,无需专线,无需 VPC 打通。OB Cloud 可为业务的主实例创建跨云的备实例,比如主实例在 AWS,备实例放在 Azure 或 GCP,系统可以创建在 Azure 或 GCP 基础设施上的备实例。备实例可通过访问主实例的对象存储中拉取日志,来实现主备之间的日志同步。
核心差异化特性:
无需专线:通过公网 + 对象存储传输日志,消除专线依赖和费用
带宽弹性:带宽随时扩缩容,不锁定固定带宽承诺
自动路由:故障切换后,业务连接配置,无需修改
四家企业的真实经历
下面四个案例覆盖了多云主备、全球化统一栈、大规模升级治理、关键系统高可靠四种典型场景,帮助大家快速参考。
案例一
作业帮—多云主备租户,切换对业务透明
作业帮是国内领先的教育科技平台,业务部署在多个公有云上,物理机分布在不同云厂商的 IDC 中,高峰期每天写入量可达近 5 万条/秒。作业帮面对的是典型的多云形态:MySQL 主从分散在不同云环境中,故障切换与连接变更对业务侧通常可感知,运维复杂度与切换风险偏高。
考虑到网络抖动的放大选主与一致性潜在风险,作业帮的多云部署避免将同一集群的多个节点跨云混合部署,取而代之的做法是,在每朵云内部署独立集群,再通过主备租户架构打通数据与切换链路。
实践中另一个关键点,是通过服务名访问与代理层路由,让切换后的连接变更尽量对应用无感知。据作业帮团队介绍,这套方案落地后带来了存储成本的显著降低,容灾切换对业务的影响程度也明显减少。无论云 1 还是云 2 的业务,都通过同一个服务名访问,obproxy 自动路由到当前主租户。发生容灾切换时,业务代码无需修改任何配置,obproxy 自动感知新主并重新路由。
成果:
存储成本节省 2/3(OceanBase 压缩 vs MySQL)
容灾切换对业务影响趋近于零
基于主备租户架构,未来可延伸支持业务单元化改造
案例链接:https://mp.weixin.qq.com/s/YxWO29ztLAKbM4Q5PuX8Ww
案例二
COROS 高驰—国内海外量多云,统一技术栈
高驰是专业运动科技品牌,覆盖全球 100+ 国家和地区,用户规模突破百万。COROS App 每天处理 GPS 轨迹、心率、血氧等海量运动数据。高驰的痛点更偏"组织与效率",国内用阿里云,海外用某主流公有云,两套完全不同的技术架构,对接工具链也不同。同一个功能迭代,需要国内外各写一套代码。国内团队面对海外云环境问题时,时区差异 + 高昂咨询成本导致响应滞后。此外,海外集群存储 20TB+,每月增长 1TB,存储账单持续膨胀。
高驰的选型目标非常明确:统一技术栈与治理体验——希望获得一致的内核能力、工具链与管理界面,不因底层云环境不同而产生割裂。做了多轮 POC,最终决定点在一句话:“选择 OceanBase 可以在多基础设施架构下实现统一的技术栈”。高驰是典型的“海外业务重度依赖非国内云厂商”的场景。当跨云主备架构消除了对某个云厂商的单点依赖后,他们不再需要在“地域故障时找谁求援”这个问题上焦虑。
落地效果:
海外 20TB+ 数据 → 压缩至 6TB 以内,存储空间节省 70%+
高峰时段弹性扩容,秒级响应
国内外团队共用同一套运维流程,协同效率显著提升
案例链接:https://mp.weixin.qq.com/s/1BjA4dVyLVSFke87umfmgw
案例三
映宇宙(映客)—2000+ 实例升级,1 个月完成国内切换
映宇宙(原映客,港交所上市)旗下业务涉及直播、婚恋、社交、短剧四大板块,并积极出海。国内用阿里云、腾讯云、火山引擎,海外用海外云厂商和一点通云,数据库有 MySQL、MongoDB、Redis、ClickHouse 等多套。
映宇宙的挑战来自规模与异构:国内 MySQL 10+ 集群、2000+ 实例,多云多数据库并存,成本与运维复杂度持续上升。直播核心业务使用金融级 MySQL RDS,成本极高,相比普通 RDS 贵数倍。此外,社交类数据量大,存储成本高,还需额外购买只读节点,海外数据库扩缩容每次延迟 10 秒以上,严重影响弹性能力,多云多技术栈让运维团队疲于奔命。
映宇宙从 2022 年 9 月开始试用 OceanBase,彼时是 3.2 版本。中间踩过坑:某实例单表超 60 万行,OceanBase 3.2 版本的内存需求甚至超过了原 MySQL。这个问题在等到 2023 年 OceanBase 新版本发布后才解决,对单实例单表支持能力超过 100 万行。升级过程中,映宇宙的研发规范发挥了关键作用——公司内部严格要求 SQL 不得使用数据库专有函数,否则无法上线。因此升级到 OceanBase(MySQL 5.6 兼容)时,绝大多数应用只需修改 SQL Mode,改造成本极低。
成果:
整体成本降低 40%-50%
存储节省最高 2/3
扩缩容延迟从 10 秒+ → 秒级响应
直播核心业务无需额外购买金融级 RDS,OceanBase 原生提供同等高可用
案例链接:https://mp.weixin.qq.com/s/NrSH9Ef9RA8sLWBdLc3DOw
案例四
理想汽车 — 制造产线 + 车云 + 自动驾驶,关键系统强调“可恢复的确定性”
理想汽车的场景跨越了制造产线、车云与自动驾驶三个领域,对数据库提出了截然不同的要求。产线系统对恢复时间高度敏感,容不得长时间中断;车云与自动驾驶场景则面对数据规模与并发的持续增长,对高可靠与高弹性提出了并行要求。
三个核心场景的挑战各不相同:
场景 1:车云系统。覆盖多地域、多家云基础设施,需要支持联网车机、远程温控、OTA 升级等高频交互,局部故障不能影响整体服务。
场景 2:产线制造系统。产线宕机每一秒都是人力资源损失,对 RTO 要求极苛刻,传统数据库故障恢复依赖人工,无法满足智能制造要求。
场景 3:自动驾驶训练数据。城市 NOA 能力上线,大模型 AI 加持下训练数据量呈井喷态势,数据存储需要高压缩,同时要可操作、可分析(HTAP)。
我们与他们一起,按场景分别治理:产线侧重点在于自动恢复与多活能力,确保故障影响面可控;云上系统则需要在多地域与多基础设施之间保持一致性,同时应对海量数据的压缩与分析需求。
结语
如果你读到这里,至少有一个问题命中了你——建议你做一次“假设今天 22:00 主库彻底不可用”的桌面演练。
不用真的断掉数据库,只需要在会议室里问清楚三个问题:
1.我们的备份在哪?格式是什么? (能不能直接用,还是需要转换?)
2.从备份恢复到“可以接受业务流量”,上一次完整演练是什么时候?耗时多少?
3.切换期间,哪几个业务是绝对不能中断的?我们有没有对这些业务的连接配置做特殊处理?
这三个问题的答案,会告诉你现在真实的容灾能力在哪个层级。如果答案让你不安,那么从多地域部署或者同城三副本 + 跨云冷备开始,是最低成本、最快落地的第一步。
云厂商是关键伙伴,他们把基础设施、网络与托管服务的可用性做到行业领先并通过 SLA 给出承诺。但从工程边界上说,SLA 覆盖的是服务组件层面的可用性,而业务连续性需要你把“数据、切换、演练、容量”整条链路工程化。哪怕可用性百分比看起来很高,落到关键业务上仍需要进一步加强。









